- 저자
- 김동형
- 출판
- 이지스퍼블리싱
- 출판일
- 2021.09.01
클래스는 객체지향 프로그래밍에서 가장 기본적인 문법 요소다. 클래스의 여러 가지 장점 중 객체지향적인 관점에서 가장 중요한 것은 '상속'이다. 상속을 이해하는 것은 객체지향적인 프로그램을 작성할 때 매우 중요하다. 상속의 개념과 상속 과정에서 메모리 구조가 어떻게 작동하는지를 제대로 이해한다면 객체의 타입 변환, 메서드 오버라이딩, super 키워드와 super() 메서드 등과 같은 클래스의 또 다른 문법 요소를 익힐 수 있을 것이다.
- 10.1 클래스 상속의 개념과 문법적 특징
- 10.2 객체의 타입 변환
- 10.3 메서드 오버라이딩
- 10.4 인스턴스 필드와 정적 멤버의 중복
- 10.5 super 키워드와 super() 메서드
- 10.6 최상위 클래스 Object
10.1 클래스 상속의 개념과 문법적 특징
클래스의 상속은 부모 클래스의 멤버(필드, 메서드, 이너 클래스)를 내려받아 자식 클래스 내부에 포함시키는 자바의 문법 요소이다.
10.1.1 상속의 개념

위 그림의 내용을 상속으로 표현하면 사람 클래스가 부모 클래스, 대학생과 직장인 클래스가 자식 클래스가 된다. 두 자식 클래스는 부모의 모든 멤버를 내려받기 때문에 대학생과 직장인 클래스 내에서는 추가 필드와 메서드만 구성하면 된다. 이와 반대로 부모 클래스는 자식 클래스들의 공통적 특징을 모아 구성한 클래스라고 생각하면 된다.
10.1.2 상속의 장점
이전 예제를 살펴보면 상속으로 이름, 나이, 먹기(), 잠자기()가 중복돼 있었지만, 상속으로 코드의 중복성이 제거됐다. 이것이 상속의 첫 번째 장점이다. 즉, 자식 클래스들의 공통적인 성분을 부모 클래스에서 한 번만 정의하는 것으로 코드가 간결해진다. 두 번째 장점은 클래스의 다형적 표현이 가능하다. 이어서 대학생과 직장인의 예로 설명한다. '대학생은 대학생이다', '대학생은 사람이다'는 모두 당연히 맞는 말이다. 따라서 1개의 객체를 여러 가지 모양으로 표현할 수 있는 특성을 다형성(Polymorphism)이라 한다. 이와 반대인 경우에는 어떨까? '사람은 대학생이다'는 맞는 표현이 아니다. 이처럼 반대 방향으로는 다형적 표현이 성립되지 않는다.
이제 상속을 표현할 때 왜 화살표가 부모 클래스를 향하는지 눈치챘을 것이다. 상속 구조도에서 화살표 방향으로는 항상 다형적 표현을 할 수 있다. 반면 화살표 방향을 거스르는 다향적 표현은 할 수 없다. 따라서 아래 그림의 A, B, C, D 클래스의 상속 구조도만 봐도 여러 다형적 표현의 가능 여부를 확인할 수 있다.

상속으로 얻을 수 있는 가장 큰 장점은 다형적 표현을 할 수 있다는 것이다. 예를 들어 사과, 포도, 키위 클래스를 만들고 각 객체를 2개, 2개, 3개씩 만들어 배열로 관리하고자 한다. 배열은 같은 자료형만 저장할 수 있으므로 어쩔 수 없이 3개의 배열 자료형을 따로 만들어 관리해야 한다. 만약 새로운 과일이 추가된다면 역시 새로운 자료형을 1개 추가하고 관리해야 한다.

사과, 포도, 키위는 모두 과일이다. 따라서 '과일'이라는 부모 클래스를 생성하고 각각에게 상속시키면 다형적 표현을 할 수 있게 된다. 즉, 다음과 같은 표현을 할 수 있게 되는 것이다.

따라서 각각의 과일로 생성한 객체를 모두 과일이라 부를 수 있게 되므로 모든 객체를 과일 배열 하나로 관리할 수 있게 된다.

객체의 다형성이 얼마나 큰 장점인지는 12장에서 추상 클래스와 인터페이스를 배울 때 더 자세히 학습한다. 지금은 '자바의 상속으로 다형적 표현을 할 수 있게 됐고, 다형적 표현의 사용으로 위와 같은 장점이 있다' 정도만 기억하자.
10.1.3 상속 문법
클래스를 상속할 때는 extends 키워드를 사용하며, 클래스명 다음에 'extends 부모클래스'를 표기한다.

자바의 클래스는 다중 상속이 불가능한데, 여기서 다중 상속은 부모 클래스가 2개 이상일 때를 말한다.

다중 상속이 불가능한 이유는 모호성(Ambiguous) 발생을 막기 위함이다.
10.1.14 상속할 때의 메모리 구조
상속받은 자식 클래스는 부모 클래스의 모든 멤버를 내려받는다고 했다. 상속받은 자식 클래스의 객체가 생성되는 메모리의 구조를 살펴보면 자연스럽게 이해할 수 있다. 다음 예를 살펴보자.
class A {
int m;
void abc() {...}
}
class B extends A {
int n;
void bcd() {...}
}클래스 A는 필드 m과 메서드 abc()를 포함하고 있고, 클래스 B는 클래스 A를 상속했으며, 필드 n과 메서드 bcd()를 추가로 정의했다. 이제 다음과 같이 자식 클래스 B의 객체를 생성했을 때의 메모리 구조를 살펴보자.
B b = new B();
클래스 영역에는 선언된 자료형의 클래스와 그 부모 클래스가 모두 로딩된다. 이때 참조변수 b는 B 자료형으로 선언됐기 때문에 힙 영역에 있는 B 타입 객체만을 가리킬 수 있게 된다. 이제 힙 영역의 실제 객체를 살펴보자. JVM은 자식 클래스의 객체를 생성할 때 가장 먼저 부모 클래스의 객체를 생성한다. 이후 자식 클래스에서 추가한 필드와 메서드가 객체에 추가됨으로써 클래스 B의 전체 객체가 완성되는 것이다. 즉, 자식 클래스 객체의 내부에는 부모 클래스 객체가 포함돼 있으므로 자식 클래스 객체에서 부모 클래스의 멤버를 사용할 수 있는 것이다.
10.1.5 생성자의 상속 여부
상속을 수행하면 부모의 모든 멤버를 내려받는다고 했다. 멤버는 클래스의 4가지 내부 구성 요소 중 생성자를 제외한 필드, 메서드, 이너 클래스를 말한다. 생성자는 자식 클래스로 상속되지 않으며 절대 상속돼서는 안된다.
class A {
...
}
class B extends A {
....
}10.1.6 객체의 다형적 표현
클래스 A를 상속받아 클래스 B를 생성(A ←B)한 예를 살펴보자. 상속 구조에서 자기 자신을 가리키거나 화살표 방향으로는 항상 다형적 표현을 할 수 있다. 따라서 이때 'A는 A이다''. 'B는 A이다' 등은 모두 가능한 표현이다. 'A는 A이다'를 코드로 표현하면 A a1 = new A()와 같이 표현할 수 있으며, 'new 키워드를 통해 A 클래스의 기본 생성자로 만든 A 객체(new A())는 A 자료형(A a1)인 a1 변수에 주소값을 저장한다.'라고 표현할 수 있다. 이와 같은 방식으로 'B는 A이다' 라고 표현할 수 있으므로 이는 코드로 A a2 = new B()와 같이 표현할 수 있다.
// 상속 관계에서 다형성의 코드 표현
A a1 = new A(); // A는 A이다.
A a2 = new B(); // B는 A이다.앞에서 말한 것처럼 생성한 객체와 동일한 타입으로 선언하는 것은 물론, 자식 클래스의 객체를 부모 클래스 타입으로 선언하는 모든 다형적 표현을 할 수 있다. 따라서 클래스 A, B, C, D가 다음과 같이 상속 구조일 때 다음의 객체 생성 코드는 모두 올바른 예이다.
// 클래스 A, B, C, D의 상속 구조
class A {}
class B extends A {}
class C extends B {}
class D extends B {}
// 다형적 표현의 올바른 예
A a = new A(); // O
B b = new B(); // O
C c = new C(); // O
D d = new D(); // O
A a1 = new B(); // O
A a2 = new C(); // O
A a3 = new D(); // O
B b1 = new C(); // O
B b2 = new D(); // O10.2 객체의 타입 변환
자바 프로그램은 등호(=)를 중심으로 항상 왼쪽과 오른쪽의 자료형이 일치해야 한다. 만약 자료형이 서로 다르다면 컴파일러가 자동으로 타입을 변환해주거나 개발자가 명시적으로 타입을 변환해 줘야 한다. 객체에서도 이러한 타입 변환이 발생하는데, 이를 각각 업캐스팅, 다운캐스팅이라 한다.
10.2.1 객체의 업캐스팅과 다운캐스팅
기본 자료형에서 업캐스팅은 범위가 좁은 쪽에서 넓은 쪽으로 캐스팅하는 것을 말하며, 다운캐스팅은 그 반대이다. 객체에서는 자식 클래스에서 부모 클래스 쪽으로 변환되는 것을 업캐스팅, 그 반대가 다운캐스팅이다. 객체는 항상 업캐스팅할 수 있으므로 명시적으로 작성하지 않아도 컴파일러가 대신 넣어준다. 하지만 다운캐스팅은 개발자가 직접 명시적으로 작성해야 한다. 기본 자료형은 다운캐스팅할 때는 넓은 범위에서 값이 좁은 범위로 변경되기 때문에 오차가 발생하긴 하지만, 문법적으로는 항상 가능했다. 하지만 객체는 명시적으로 적어 준다고 해도 다운캐스팅 자체가 안될 때가 있다. 잘못된 다운캐스팅을 수행하면 ClassCastException 예외가 발생하고, 프로그램이 종료된다. 우선 업캐스팅은 왜 항상 가능하고, 다운캐스팅은 되는 경우도 있고 안되는 경우도 있는지 사람과 학생을 통해 학습하자.

업캐스팅은 말로 표현하면 '사람은 학생이다'으로 당연히 항상 성립하는 말이다. 반면 '사람은 학생이다'는 화살표를 거스르는 방향이므로 틀린 표현이라고 했다. 하지만 정확히 표현하면 '항상 성립하는 것은 아니다' 정도의 표현이 적절하다. 즉, 사람 중에는 학생인 사람이 있고, 아닌 사람도 있다. 학생인 사람 객체는 학생으로의 다운캐스팅이 가능할 것이고, 학생이 아닌 사람 개체는 불가능할 것이다. 이 말이 이해됐다면 이제 코드로 확인해보자. 도대체 '학생인 사람'은 코드에서 어떻게 표현될까? 여기에 2개의 사람 객체가 있다.
사람 human1 = new 사람(); // 학생과 학생이 아닌 사람이 모두 포함된 사람 객체
사람 human2 = new 학생(); // 학생인 사람 객체각각 사람, 학생 객체를 생성하고 모두 동일한 사람 타입의 자료형을 갖지만 힙 영역에 생성된 객체의 모양은 다르다. 첫 번째 객체인 human1은 실제 사람 객체로 생성했으므로 여기에는 사람들의 공통된 속성과 기능들만 포함돼 있을 것이다. 이때 human1은 학생으로의 다운캐스팅은 불가능하다. 학생으로의 다운캐스팅이 가능하려면 객체 내부에 학생의 속성(학번 등)과 기능(등교하기() 등)이 포함돼 있어야 하는데, 애초에 human1의 객체에는 이것들이 포함돼 있지 않기 때문이다. 반면 human2는 실제 학생() 생성자를 이용해 객체를 생성했으므로 객체 내부에는 사람의 공통된 특성뿐 아니라 학생의 속성과 기능이 포함돼 있다. 따라서 human2도 사람 자료형으로 저장돼 있지만, 학생으로의 다운캐스팅이 가능하다.
다른 예를 살펴보자. 클래스 A, B, C의 상속 관계는 다음과 같다.

업캐스팅일 때는 다음과 같다. 객체를 B() 생성자로 생성하면 B를 기준으로 부모 클래스 방향이 업캐스팅되므로 A로는 캐스팅할 수 있을 것이다. 만일 객체를 C() 생성자로 생성하면 A와 B 모두로 캐스팅할 수 있다. 업캐스팅이므로 심지어 생략해도 컴파일러가 추가해 준다.

다운캐스팅일 때를 살펴보자. 다운캐스팅은 컴파일러가 자동으로 추가하지 않으므로 등호를 중심으로 좌우의 자료형이 동일하도록 명시적으로 캐스팅을 수행해야 문법 오류가 발생하지 않는다.

A() 생성자로 만든 A 타입은 B 타입으로 다운캐스팅할 수 없다. 문법적으로는 오류가 발생하지 않지만, 실행 이후 실제 캐스팅 과정에서 ClassCastException 예외가 발생한다. 실제 객체가 A 타입으로 만들어져 있기 때문이다. 반면 B() 생성자로 만든 A 타입은 B 타입으로의 다운캐스팅할 수 있다. 객체 자체가 B 타입으로 만들어져 있기 때문이다. 이와 같은 맥락에서 볼 때 B() 생성자로 만든 A 타입을 C 타입으로 다운캐스팅할 수 없다.
다소 복잡해 보이지만, 캐스팅의 가능 여부는 무슨 타입으로 선언돼 있는지는 중요하지 않으며 new 키워드에 의해 어떤 생성자로 생성됐는지가 중요하다. 실제 생성된 객체의 위쪽(업캐스팅 방향)에 있는 모든 클래스 타입으로는 항상 캐스팅을 할 수 있다. 예를 들어 이 예제에서 B() 생성자로 만들었으면 A로 캐스팅할 수 있으며, C()로 만들었다면 A와 B로 캐스팅을 할 수 있다.
10.2.2 메모리로 이해하는 다운캐스팅
메모리 구조와 함께 다운캐스팅 과정을 살펴보자. 메모리에서의 동작만 잘 이해하면 캐스팅의 가능 여부뿐 아니라 선언된 타입에 따른 차이점까지 한 번에 파악할 수 있다.

먼저 A a = new B()를 살펴보면 실제 객체는 B() 생성자로 만들었다(new B())는 것을 알 수 있다. 앞의 상속에서 설명한 것 처럼 자식 클래스의 생성자를 호출하면 부모 클래스의 객체를 먼저 생성한다고 했으므로 A 객체가 먼저 메모리에 만들어지고, 이후 B 객체가 완성될 것이다. 즉, 위의 그림처럼 B 객체 속에 A 객체를 품고 있는 모양이다.
그런데 이 객체를 A 타입의 참조변수로 가리키고 있다.(A a)이때 실제 참조변수는 힙 영역의 B 객체 안에 있는 A 객체를 가리키게 된다. 이는 매우 중요하다. 선언된 타입이 의미하는 바는 실제 객체에서 자신이 선언된 타입의 객체를 가리키게 되는 것이다. 이제 B b = (B) a와 같이 A 타입의 a를 B 타입으로 캐스팅해 B 타입으로 저장하고자 한다. 즉, a는 A 객체를 가리켰지만, (B) a는 B 객체를 가리켜야 하는 것이다. 힙 영역에는 이미 B 객체가 있으므로 B 타입을 가리키는 것이 전혀 문제가 없는 것이다. 반면 C c = (C) a와 같이 C 타입으로 캐스팅해보자. 그렇게 되면 참조변수 c는 이제 C 타입을 가리켜야 하는데, 힙 영역에는 C 타입 객체가 만들어진 적이 없다. 따라서 C 타입으로는 다운캐스팅할 수 없다. 이와 같은 이유로 캐스팅의 가능 여부를 확인하기 위해 실제 어떤 생성자로 만들었는지가 중요한 것이다.
10.2.3 선언 타입에 따른 차이점
다운캐스팅을 메모리 구조상에서 이해했다면 선언 타입에 따른 차이점은 어렵지 않게 이해할 수 있을 것이다.
다음과 같은 2개의 클래스가 있다고 가정하자.
class A {
int m = 3;
void abc() {
System.out.println("A");
}
}
class B extends A {
int n = 4;
void bcd() {
System.out.println("B");
}
}이제 동일하게 B()의 생성자로 객체를 생성하고, 이를 B 타입과 A 타입으로 각각 선언했을 때의 차이점을 알아보자.
먼저 B b = new B()일 때를 살펴보자.
// B의 객체를 b 타입으로 선언했을 때
B b = new B();
System.out.println(b.m); // O
System.out.println(b.n); // O
b.abc(); // O
b.bcd(); // O
B() 생성자로 생성했으므로 힙 영역에는 A 객체를 감싸고 있는 B 객체가 생성될 것이다. A 객체의 내부에는 m과 abc()가 있고, B 객체에는추가로 n과 bcd()가 있다. 결국 B 객체 내부에 m, n, abc(), bcd()가 있는 형태이다. 참조 변수가 B 타입으로 선언돼 있으므로 참조 변수 b는 B 객체를 가리키게 되고, 이때 참조변수를 이용해 2개의 필드와 2개의 메서드를 모두 사용할 수 있다. 그럼 이제 A a = new B()일 때를 살펴보자.
// B의 객체를 A 타입으로 선언했을 때
A a = new B();
System.out.println(b.m); // O
System.out.println(b.n); // X
b.abc(); // O
b.bcd(); // X
B() 생성자로 객체를 생성하는 것은 동일하므로 힙 영역에 생성되는 객체의 모양은 동일할 것이다. 하지만 참조 변수가 A 타입으로 선언돼 있으므로 실제로 힙 메모리에 B 객체가 있더라도 참조변수 a는 A 객체만을 가리킬 것이다. 따라서 이 경우에는 m과 abc()만 사용할 수 있다.
10.2.4 캐스팅 가능 여부를 확인하는 instanceof 키워드
캐스팅할 수 있는지를 확인하려면 실제 객체를 어떤 생성자로 만들었는지와 클래스 사이의 상속 관계를 알아야 한다. 하지만 다른 사람이 만든 클래스를 사용할 때는 이런 정보를 하나씩 모두 확인하는 일은 정말 복잡하고 어렵다. 이를 위해 자바는 캐스팅 가능 여부를 불리언 타입으로 확인할 수 있는 문법 요소를 제공하고 있는데, 이것이 바로 instanceof이다.
// 캐스팅 가능 여부 확인
참조변수 instanceof 타입 // true: 캐스팅 가능 / false: 캐스팅 불가능C c = new C();
System.out.println(c instanceof A); // true
System.out.println(c instanceof B); // true
System.out.println(c instanceof C); // true이렇게 instanceof 키워드를 사용하면 상속 관계나 객체를 만든 생성자를 직접 확인하지 않고도 캐스팅 가능 여부를 확인할 수 있다. 따라서 잘못된 캐스팅에 따른 실행 예외(ClassCastException)로 프로그램이 종료되는 것을 방지하기 위해 일반적으로 다운캐스팅을 수행할 때 instanceof를 이용해 캐스팅 가능 여부를 확인하고, 가능한 때만 캐스팅을 수행한다.
10.3 메서드 오버라이딩
10.3.1 메서드 오버라이딩의 개념과 동작
메서드 오버라이딩(Method Overriding)은 부모 클래스에게 상속받은 메서드와 동일한 이름의 메서드를 재정의하는 것으로, 부모의 메서드를 자신이 만든 메서드로 덮어쓰는 개념이다. 메서드 오버라이딩이 수행되기 위해서는 다음 2가지 조건을 만족해야 한다.
- 부모 클래스의 메서드 시그니처 및 리턴 타입이 동일해야 한다.
- 부모 클래스의 메서드 접근 지정자의 범위가 같거나 넓어야 한다.
먼저 부모 클래스의 메서드 시그니처(메서드명, 입력매개변수의 타입과 개수)뿐 아니라 리턴 타입까지 완벽하게 일치해야 한다. 두 번째 조건은 오버라이딩하려는 부모의 메서드보다 같거나 넓은 범위의 접근 지정자를 가져야 한다.
다음 예를 살펴보자. 클래스 A 내부에는 print() 메서드를 포함하고 있으며, 클래스 B는 클래스 A를 상속받은 후 print() 메서드를 다시 재정의함으로써 오버라이딩했다.
class A {
void print() {
System.out.println("A 클래스");
}
}
class B extends A {
@Override
void print() {
System.out.println("B 클래스");
}
}먼저 A aa = new A()와 같이 객체를 생성했을 때 메모리에서 일어나는 일을 살펴보자.

먼저 힙 영역에 A() 생성자로 객체가 생성되고, 이를 A 타입으로 선언한 참조 변수 aa는 이 객체를 가리키고 있을 것이다. A 객체 내에는 print() 메서드가 있지만, 객체 내의 메서드는 실제 메서드의 위치 정보만 저장돼 있고, 실제 print()는 메서드 영역에 정의돼 있다. 당연히 aa.print()를 실행하면 "A 클래스"가 출력될 것이다. 이제 B bb = new B()일 때를 살펴보자.

B() 생성자가 호출되면 우선 부모 클래스인 객체가 힙 영역에 먼저 생성되므로 이 과정에서 A 객체 내의 print()가 메서드 영역에 생성될 것이다. 이후 B 객체가 생성되는데, 여기에서 print() 메서드를 추가했다. B 객체의 print() 역시 메서드 영역에 저장되는데, 이때는 이미 A 객체를 생성하는 과정에서 print() 메서드가 존재하고 있는 상황이다. 이때 B 객체의 print() 메서드가 이미 있는 A 객체의 print() 메서드를 덮어쓰기, 즉 오버라이딩하게 되는 것이다. 이제 bb.print()를 실행하면 bb 객체 내부의 print() 메서드가 가리키는 곳에 가서 print() 메서드가 실행된다. 메서드 영역의 print() 메서드는 이미 B의 print() 메서드로 오버라이딩된 이후이므로 당연히 "B 클래스"가 출력될 것이다.
오버라이딩은 덮어쓰기와 똑같은 개념인가요?
오버라이딩을 개념상 덮어쓰기라고 설명하고 있지만, 사실 덮어쓰기와 오버라이딩은 차이가 있다. 덮어쓰기는 이전 파일이 완전히 삭제되고, 새로운 파일로 바뀌는 것이다. 반면 오버라이딩은 이전의 print() 메서드 위에 새로운 메서드가 올라(over) 타고(riding) 있다고 생각하면 된다. 그래서 원할 때 밑에 깔려 있는 A 객체의 print() 메서드도 호출할 수 있다. 이 부분은 나중에 다시 설명하기로 하고, 여기서는 B의 print()가 A의 print()를 덮어썼다고 생각하면 된다. 이제 가장 중요한 A ab = new B()일 때를 고려해보자.

객체를 B() 생성자로 생성했지만, A 타입으로 참조 변수를 선언했을 때다. B() 생성자로 객체를 생성하므로 부모 클래스인 A 객체가 만들어지고, 이후 B의 객체가 만들어진다. 이 과정에서 메서드 영역에는 print() 메서드의 오버라이딩이 발생한다. 앞의 B bb = new B()와 객체 생성 과정은 같다. 다만 다른 점은 A 타입의 참조 변수를 사용하고 있으므로 참조 변수는 A 객체를 가리키고 있다는 것이다. 따라서 ab.print()는 실제 A 객체의 print() 메서드를 호출하는 것이다. 하지만 A 객체의 print() 메서드가 가리키는 곳은 이미 B의 print()로 오버라이딩된 이후이므로 A 객체 내부의 print()가 실행됐는데도 ab.print()의 결과값으로 "B 클래스"가 출력되는 것이다.
class A {
void print() {
System.out.println("A 클래스");
}
}
class B extends A {
@Override
void print() {
System.out.println("B 클래스");
}
}
public class MethodOverriding_1 {
public static void main(String[] args) {
// A 타입 / A 생성자
A aa = new A();
aa.print(); // A 클래스
// B 타입 / B 생성자
B bb = new B();
bb.print(); // B 클래스
// A 타입 / B 생성자
A ab = new B();
ab.print(); // B 클래스
}
}10.3.2 메서드 오버라이딩을 사용하는 이유
메서드 오버라이딩은 왜 사용하는 것일까? 다음 예를 보면 직관적으로 이해할 수 있다. 먼저 부모 클래스로 Animal(동물) 클래스를 생성하고, 이 클래스를 상속받는 자식 클래스로 Bird(새)와 Cat(고양이) 그리고 Dog(개) 클래스를 생성했다.

4개의 클래스 모두 cry() 메서드를 포함하고 있다. Animal 클래스 내부의 cry() 메서드는 아무런 내용도 포함하고 있지 않으며, 나머지 자식 클래스에는 각각 자신만의 울음소리를 출력하는 내용이 들어 있다. 이제 부모 클래스를 포함해 모든 클래스의 객체를 선언하고, 각각의 타입을 객체의 타입과 일치시켜 놓았다. 이때 각각의 객체의 cry() 메서드를 실행하면 당연히 각각의 울음소리가 출력될 것이다.
// 각각의 타입으로 선언 + 각각의 타입으로 객체 생성
Animal aa = new Animal();
Bird bb = new Bird();
Cat cc = new Cat();
Dog dd = new Dog();
aa.cry(); // 출력 없음.
bb.cry(); // 짹짹
cc.cry(); // 야옹
dd.cry(); // 멍멍이때 참조 변수 ab, ac, ad는 모두 Animal 타입이지만, 각각 서로 다른 메서드로 오버라이딩 됐으므로 각각의 cry() 메서드는 서로 다른 출력 결과를 보인다. 여기서 꼭 알아야 할 것은 Animal 클래스 내부에 아무런 기능도 수행하지 않는 cry() 메서드가 있는 이유다. 다형적 표현으로 자식 클래스들의 객체를 부모 클래스인 Animal 타입으로 선언할 수는 있지만, 이렇게 되면 Animal 내부의 메서드만 사용할 수 있다. 즉, 만일Animal 클래스 내부에 cry() 메서드가 없었다면, 어떤 참조 변수도 cry()를 호출할 수 없을 것이다. 이것이 아무런 기능도 수행하지 않는데도 Animal 클래스 내부에 cry() 메서드를 넣어 둔 이유다. 이렇게 모든 객체를 부모 타입 하나로 선언하면 다음처럼 배열로 한 번에 관리할 수 있다는 장점이 있다.
// 배열로 한 번에 관리 가능
Animal[] animals = new Animal[] { new Bird(), new Cat(), new Dog() };
for (Animal animal : animals) {
animal.cry(); // 짹짹, 야옹, 멍멍
} 부모 클래스에 선언한 cry() 메서드는 단순히 자식 클래스에서 호출하기 위한 용도다. 그렇다면 굳이 메서드의 원형을 지켜가면서 작성할 필요가 없을 것이다. 그래서 나온 문법이 12장의 '추상abstract 메서드'다.
10.3.3 메서드 오버라이딩과 메서드 오버로딩
간혹 메서드 오버라이딩(overriding)과 메서드 오버로딩(overloading)을 혼동할 때가 있다. 오버로딩은 이름이 동일하지만, 시그너처가 다른 여러 개의 메서드를 같은 공간에 정의하는 것을 말한다.
class A {
void print1() {
System.out.println("A 클래스 print1");
}
void print2() {
System.out.println("A 클래스 print2");
}
}
class B extends A {
void print1() { // 메서드 오버라이딩
System.out.println("B 클래스 print1");
}
void print2(int a) { // 메서드 오버로딩
System.out.println("B 클래스 print2");
}
}클래스 A에는 print1()과 print2() 메서드가 있다. 클래스 A를 상속받은 클래스 B에서는 print1()과 print2(int a)를 추가로 정의했다. 이때 클래스 B에서는 몇 개의 메서드를 사용할 수 있을까? 정답은 3개다. print1()은 상속받은 메서드와 리턴 타입과 시그너처가 완벽하게 동일하므로 오버라이딩된다. 반면 클래스 A에게 상속받은 print2() 메서드는 입력매개변수가 없는 print2( 메서드이며, 클래스 B에서 추가로 정의한 메서드는 입력매개변수로 정수값을 1개 받는 print2(int a)이므로 메서드 시그너처가 다르다. 즉, print2() 메서드는 오버로딩되는 것이다. 결과적으로 클래스 B 내부에서는 print1(), print2(), print2(int a)를 사용할 수 있다.
10.3.4 메서드 오버라이딩과 접근 지정자
자식 클래스가 부모 클래스의 메서드를 오버라이딩할 때는 반드시 상속받은 메서드의 접근 지정자와 범위가 같거나 넓은 접근 지정자를 사용해야 한다. 즉, 접근 지정자의 범위를 좁힐 수 없다는 말이다. 예를 들어 부모 클래스의 메서드가 default 접근 지정자를 포함하고 있을 때 자식 클래스는 default 접근 지정자와 같거나 큰 범위의 접근 지정자, 즉 protected, public, default 접근 지정자만 사용할 수 있다.
| 부모 클래스 메서드의 접근 지정자 | 메서드 오버라이딩을 할 때 사용할 수 있는 접근 지정자 |
| public | public |
| protected | public, protected |
| default | public, protected, default |
| private | public, protected, default, private |
10.4 인스턴스 필드와 정적 멤버의 중복
10.3절에서는 오버라이딩을 알아봤다. 정확히 말하면 메서드 오버라이딩이다. 즉, 메서드만 오버라이딩된다는 말이다. 그런데 만일 부모 클래스에서 상속받을 필드명과 동일한 필드명을 추가하면 어떻게 될까? 또는 정적 메서드도 오버라이딩이 될까? 정답부터 말하면, 인스턴스 필드나 정적 멤버(정적 필드와 정적 메서드)는 자식 클래스에서 동일한 이름으로 정의해도 오버라이딩되지 않는다. 메모리 구조를 보면서 그 이유를 하나씩 알아보자.
10.4.1 인스턴스 필드의 중복
먼저 인스턴스 필드가 중복될 때를 살펴보자.
class A {
int m = 3;
}
class B extends A {
int m = 4;
}이때 메서드 오버라이딩과 마찬가지로 3가지 메모리 동작을 살펴보자. 먼저 A a = new A()일 때이다.

A() 생성자로 생성하고, A 타입으로 선언했으므로 B는 쳐다볼 필요도 없다. 힙 영역에는 m = 3인 필드를 포함하고 있는 객체가 생성되며, A 타입으로 선언돼 있으므로 참조 변수는 이 A 타입의 객체를 가리키고 있을 것이다. 따라서 a.m은 당연히 3의 값이 나올 것이다. 이제 B b =new B(), 즉 B() 생성자로 객체를 생성하고, B 타입으로 선언했을 때다.

B()로 B 객체를 생성하는 과정에서 먼저 부모 객체인 A 객체가 먼저 생성될 것이다. A 객체가 생성된 후 클래스 B에서 추가한 내용을 포함하는 객체가 만들어질 것이다. 메모리를 살펴보면 B 객체 속에는 필드 m의 값이 2개 존재한다. 1개는 부모 클래스에서 만든 필드 m(=3), 1개는 자식 클래스에서 만든 필드 m(=4)이다. 인스턴스 필드는 이름이 중복되더라도 객체 내의 각각의 공간 속에 저장된다. 즉, 저장 공간이 완벽하게 분리돼 있으므로 오버라이딩은 발생하지 않는다. B 타입으로 참조 변수를 선언했으므로 외부의 B 객체를 가리키고 있을 것이다. 그렇다면 b.m의 값은 무엇일까? 이때 항상 가리키고 있는 객체 테두리에서 안쪽으로 들어가면서 만나는 첫 번째 값이 실행된다. 여기서는 B 객체를 가리키고 있으므로 b.m은 B 객체의 m 값을 의미한다. 따라서 4의 값을 가리키게 되는 것이다.
메서드의 경우 객체 내의 메서드 위치를 저장하는 공간은 분리돼 있지만, 실제 메서드가 저장되는 공간은 인스턴스 메서드 영역 한 곳이므로 오버라이딩이 발생하는 것이다. 마지막으로 A a = new B()로 객체를 생성했을 때를 살펴보자.

이때 힙 영역에 생성되는 객체의 모양은 바로 이전 예시와 동일하며, 선언된 참조 변수의 타입만 다르다. 여기에서는 A 타입으로 선언됐기 때문에 A 객체를 가리키고 있을 것이다. A 객체에는 1개의 m 값(=3)만 포함하고 있으므로 ab.m = 3의 결과가 나타난다. 이상의 내용을 정리하면, 인스턴스 필드는 상속받은 필드와 동일한 이름으로 자식 클래스에서 정의해도 각각의 저장 공간에 저장되므로 오버라이딩은 발생하지 않는다.
10.4.2 정적 필드의 중복
이번에는 정적(static) 필드를 살펴보자. 정적 필드의 저장 공간은 정적 영역의 클래스 내부에 만들어지고, 모든 객체가 공유한다고 했다. 다음 예에서 클래스 A는 정적 필드 m = 3을 포함하고 있고, 이를 상속한 클래스 B에서도 동일한 이름의 정적 필드 m = 4를 정의했다. 결론부터 말하자면, 상속할 때 정적 필드명을 중복해 정의해도 저장 공간이 불리돼 있으므로 오버라이딩은 발생하지 않는다.
// 정적 필드의 중복
class A {
static int m = 3;
}
class B extends A {
static int m = 4;
}
public class OverlapStaticField {
public static void main(String[] args) {
// 클래스명으로 바로 접근
System.out.println(A.m);
System.out.println(B.m);
System.out.println();
// 객체 생성
A aa = new A();
B bb = new B();
A ab = new B();
// 생성한 객체로 정적 필드 호출
System.out.println(aa.m); // 3
System.out.println(bb.m); // 4
System.out.println(ab.m); // 3
}
}10.4.3 정적 메서드의 중복
인스턴스 메서드가 오버라이딩됐던 이유는 동일한 공간에 동일한 이름의 메서드를 저장했기 때문이다. 하지만 정적 메서드는 정적 필드와 마찬가지로 각자의 클래스 내부에 존재한다. 즉, 다른 공간에 저장되는 것이다. 부모 클래스의 정적 메서드는 부모 클래스의 내부, 자식 클래스의 정적 메서드는 자식 클래스의 내부에 저장된다. 따라서 부모 클래스의 정적 메서드와 동일한 이름으로 자식 클래스에서 정의한다 하더라도 절대 오버라이딩되지 않는다. 정적 메서드가 메모리상에서 동작하는 모습은 정적 필드와 동일하므로 자세한 설명은 생략한다.
// 정적 필드의 중복
class A {
static void print() {
System.out.println("A 클래스");
}
}
class B extends A {}
static void print() {
System.out.println("B 클래스");
}
}
public class OverlapStaticField {
public static void main(String[] args) {
// 클래스명으로 바로 접근
A.print(); // A 클래스
B.print(); // B 클래스
System.out.println();
// 객체 생성
A aa = new A();
B bb = new B();
A ab = new B();
// 객체를 통한 메서드 호출
aa.print(); // A 클래스
bb.print(); // B 클래스
ab.print(); // A 클래스
}
}10.4.4 인스턴스 멤버와 정적 멤버의 중복 정리
지금까지 상속 과정에서 부모의 인스턴스 필드, 인스턴스 메서드, 정적 필드, 정적 메서드와 동일한 이름으로 자식 클래스에서 멤버를 재정의했을 때 일어나는 상황을 알아봤다. 객체의 생성 과정을 메모리상으로 표현할 수 있다면 외우지 않아도 쉽게 이해할 수 있겠지만, 아직 완전히 이해하지 못했다면 그림 10-21을 보면서 정리된 결과라도 꼭 기억해 두자.

여기서 기준점은 '값을 읽을 때의 기준'을 의미한다. 예를 들어 인스턴스 필드 m이 클래스 A와 클래스 B에 모두 있다면 A a = new B()와 같이 표현했을 때 인스턴스 필드의 기준점은 선언 타입이므로 a.m은 클래스 A의 필드값을 가리키는 것이다. 나머지 멤버도 이와 마찬가지로 이해하면 된다. 즉, 인스턴스 메서드는 객체가 어떤 생성자로 생성됐는지, 나머지는 어떤 타입으로 선언됐는지가 기준이 되는 것이다.
10.5 super 키워드와 super() 메서드
this 키워드와 this() 메서드는 클래스 자신의 내부 구성 요소를 호출하는 문법 요소다. 다시 한번 정리하면, this는 자기 객체를 가리키는 참조 변수명으로 인스턴스 메서드 내부에서 필드를 사용하거나 메서드를 호출할 때 참조 변수명으로 사용하고, 생략했을 때 컴파일러가 자동으로 추가해 준다고 했다. this() 메서드는 자신의 또 다른 생성자를 호출하고, 생성자 내에서만 사용할 수 있으며, 항상 첫 줄에 위치해야 한다고 했다. 한마디로 정리하면 this는 자신의 객체, this()는 자신의 생성자를 의미한다. 이와 달리 super는 부모의 객체, super()는 부모의 생성자를 의미한다. super와 super()는 모두 부모 클래스와 관련이 있으므로 상속 관계에서만 사용할 수 있다.
10.5.1 부모의 객체를 가리키는 super 키워드
class A {
void abc() {
System.out.println("A 클래스의 abc()");
}
}
class B extends A {
void abc() {
System.out.println("B 클래스의 abc()");
}
void bcd() {
abc(); // this.abc();
}
}
public class SuperKeyword_1 {
public static void main(String[] args) {
// 객체 생성
B bb = new B();
// 메서드 호출
bb.bcd(); // B 클래스의 abc()
}
}그렇다면 부모 클래스의 abc()를 자식 클래스에서 호출할 수 있을까? 이때 사용하는 것이 바로 super 키워드다. 다음 예를 살펴보자. super는 부모의 객체를 말하는 것이므로 명시적으로 super.abc()라고 작성하면 부모의 abc()를 호출할 수 있다.
...
void bcd() {
super.abc(); // this.abc();
}
...
// 객체 생성
B bb = new B();
// 메서드 호출
bb.bcd(); // A 클래스의 abc()10.5.2 부모 클래스의 생성자를 호출하는 super() 메서드
클래스 A를 상속받아 클래스 B를 생성하고, B() 생성자를 이용해 객체를 생성할 때 항상 부모 클래스 객체가 먼저 생성된다고 했다. 그런데 어떻게 자식 클래스 생성자로 부모 클래스 객체를 먼저 만들 수 있었을까? 이것이 바로 super() 메서드의 역할이다. super()는 부모 클래스의 생성자를 호출한다. this()와 마찬가지로 생성자의 내부에서만 사용할 수 있고, 반드시 첫 줄에 와야 한다. this() 메서드도 생성자의 첫 줄에만 올 수 있으므로 이 둘은 1개의 생성자에서 절대로 같이 쓸 수 없을 것이다. 다음 예제를 살펴보자.
// super()를 이용한 부모 클래스 생성자 호출
class A {
A() {
System.out.println("A 생성자");
}
}
class B extends A {
B() {
super();
System.out.println("B 생성자");
}
}B b = new B()와 같이 B() 생성자로 객체를 생성했을 때의 메모리 구조는 다음과 같다.

B() 생성자를 이용해 객체를 생성할 때는 가장 먼저 super() 메서드를 실행하고 있다. super()는 부모의 생성자를 호출하는 것이므로 A()가 실행될 것이다. A() 생성자의 실행이 완료되면 메모리에는 A 객체가 생성될 것이다. 이후 다시 돌아와 나머지 코드를 실행한다. 따라서 B b = new B()와 같이 객체를 생성하면 값이 "A 생성자", "B 생성자" 순으로 출력된다.
super() 메서드로 호출하는 대상은 super 대신 부모 클래스명을 대입하면 된다. 예를 들어 super()→A(), super(3)→A(3)이다.
여기서 매우 중요한 사실은 모든 생성자의 첫 줄에는 반드시 this() 또는 super()가 있어야 한다는 것이다. 만일 아무것도 써 주지 않으면 컴파일러는 super()를 자동으로 삽입한다. 즉, 생성자를 호출할 때는 항상 부모 클래스의 생성자가 한 번은 호출된다는 것이다. 이게 바로 자식 클래스의 생성자로 객체를 생성할 때 부모 클래스의 객체가 만들어지는 이유다. super()가 자동으로 추가되는지를 바로 확인할 수 있는 방법이 있다. 다음 예제를 살펴보자.

클래스 A에는 int 값을 받는 생성자가 1개 정의돼 있다. 기본 생성자는 아니더라도 생성자가 있으므로 컴파일러는 기본 생성자를 추가해주지 않을 것이다. 이제 클래스 B를 정의하고, 클래스 A를 상속하면 내부에 아무런 코드를 작성하지도 않았는데 상속받자마자 오류가 발생한다. 그 이유는 무엇일까?
클래스 B 안에는 생성자가 없으므로 컴파일러가 기본 생성자를 자동으로 삽입해 줄 것이다. 또한 모든 생성자의 첫 줄에는 this() 또는 super()가 있어야 하므로 컴파일러는 추가로 기본 생성자의 첫 줄에 super() 메서드를 추가한다. 앞에서 설명한 것처럼 super()는 부모의 기본 생성자, 즉 A()를 호출하라는 의미다. 하지만 클래스 A는 기본 생성자를 포함하고 있지 않으므로 오류가 발생하는 것이다. 이를 해결하기 위해서는 클래스 B에 생성자를 직접 작성하고 첫 줄에 super(3)과 같이 정수를 입력받는 부모의 생성자를 명시적으로 호출해야 한다.
10.6 최상위 클래스 Object
자바의 모든 클래스는 Object 클래스를 상속받는다. 즉, Object 클래스는 자바의 최상위 클래스다. 조금 의아해할 수도 있다. 우리는 상속을 배웠지만 한 번도 Object 클래스를 상속한 적이 없었기 때문이다. 실제로 컴파일러는 아무런 클래스로 상속하지 않으면 자동으로 extends Object를 삽입해 Object 클래스를 상속한다. 즉, 다음과 같이 클래스 A를 상속받아 클래스 B를 만들었을 때 부모 클래스인 클래스 A는 아무것도 상속하지 않았다. 이렇게 되면 컴파일러는 extends Object를 삽입하고 결국 Object←A←B의 상속 관계가 만들어진다. 자바에서는 다중 상속을 할 수 없으므로 클래스 A를 이미 상속하고 있는 클래스 B Object를 직접 상속받을 수 없다.

따라서 자바의 모든 클래스는 어떤 객체로 만들든지 다음과 같이 Object 타입으로 선언할 수 있게 된다.
// 임의의 클래스를 Object 타입으로 선언하는 예
Object oa = new A();
Object ob = new B();이것은 정말 중요한 장점이다. 메서드 오버로딩을 설명할 때 살펴본 System.out.println() 메서드를 다시 살펴보자. println() 메서드는 다양한 타입을 출력하기 위해 여러 개의 입력매개변수 타입으로 오버로딩돼 있었다. 만일 10개의 타입을 출력하는 기능을 부여하려면 10개의 메서드로 오버로딩해 놓아야 한다. 하지만 이상한 점은 System.out.println(new A())와 같이 사용자가 직접 만든 클래스 타입도 출력할 수 있다는 것이다. 이것이 가능한 이유는 무엇일까? 자바가 사용자가 만들 타입을 미리 생각해 오버로딩해 놓을 수는 없다. 여기에 Object 클래스의 비밀이 숨어 있다. System.out.println(Object x)가 바로 그 해답이다.

즉, 기본 자료형 이외에 Object를 입력매개변수로 하는 println() 메서드를 오버로딩해 놓은 것이다. 이렇게 되면 사용자가 어떤 클래스 타입의 객체를 생성하더라도 다형성에 따라 Object 타입이라고 불릴 수 있으므로 입력매개변수로 모든 타입의 객체를 받아들일 수 있는 것이다.
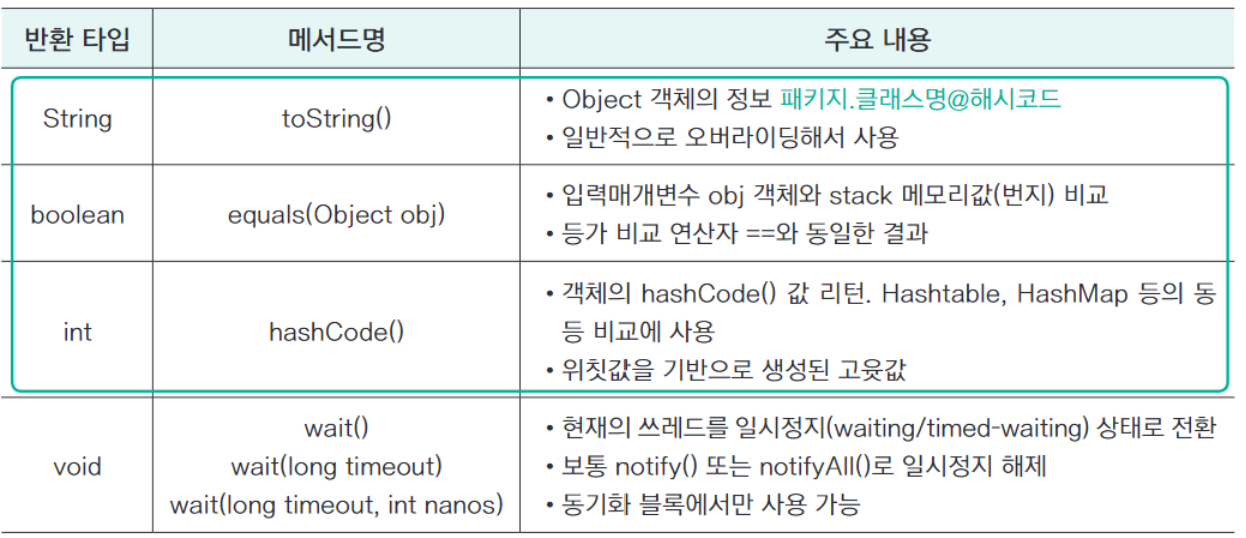
10.6.1 Object 클래스의 주요 메서드
앞에서 이야기한 것처럼 Object 클래스는 자바의 최상위 부모 클래스다. 이는 자바의 모든 클래스가 Object 클래스의 메서드를 포함하고 있다는 것을 의미한다. 그럼 Object 클래스의 대표적인 메서드를 알아보자.

'자바 > Do it! 자바 완전 정복' 카테고리의 다른 글
| Do it! 자바 완전 정복: 12장 추상 클래스와 인터페이스 (1) | 2025.01.31 |
|---|---|
| Do it! 자바 완전 정복: 11장 자바 제어자 2 (0) | 2025.01.31 |
| Do it! 자바 완전 정복: 9장 자바 제어자 1 (0) | 2025.01.31 |
| Do it! 자바 완전 정복: 8장 클래스 외부 구성 요소 (1) | 2025.01.31 |
| Do it! 자바 완전 정복: 7장 클래스 내부 구성 요소 (0) | 2025.01.31 |



